北京紫光科技服务集团有限公司
瑞得万(北京)国际卡丁车场
小米生态链公司米物科技(响应式)
贝瑞和康
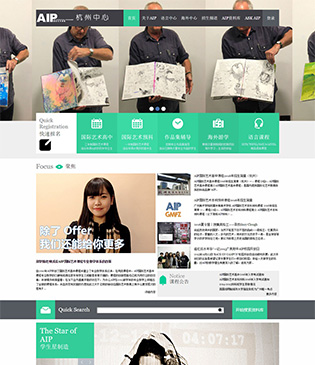
中国美术学院-AIP杭州课程
北京顺义区市政控股集团
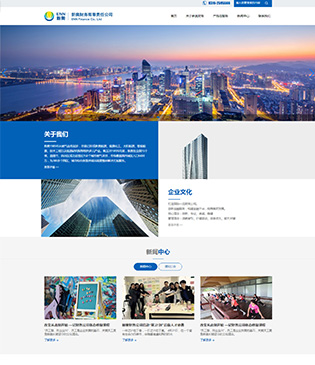
新奥财务有限公司
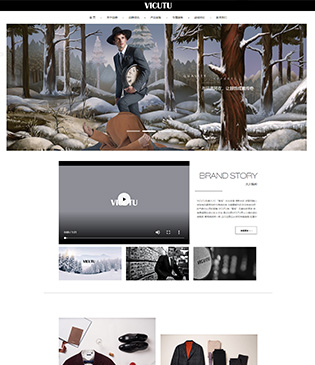
威克多服饰
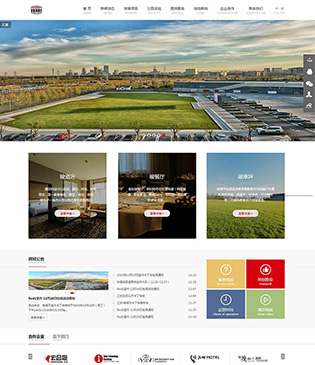
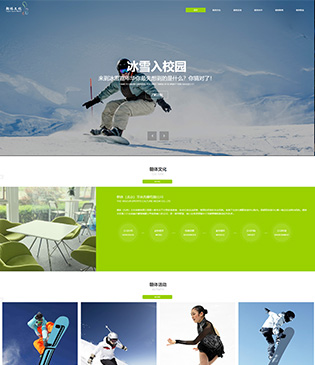
宏昌竣体育休闲公园
元艺术馆(游艺术)网站制作
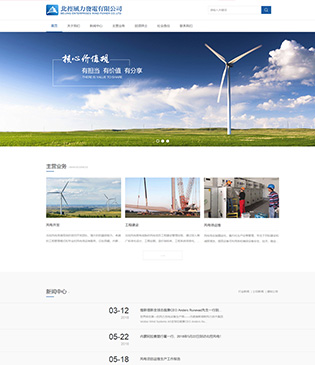
北控风力发电有限公司
国家文物局水下文化保护中心
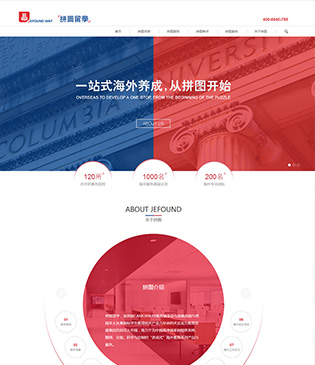
拼图留学
朝体(北京)文化传媒有限公司
企业官网是企业在互联网上展示自身形象、传达信息、与客户进行互动的重要平台。因此,良好的企业官网建设方案对于企业发展至关重要。本文将从五个方面,即网站目标、定位、功能、设计和推广,探讨企业官网建设的方案。 随时可以获取和发布商业信息,寻找潜在客户,促成成交,有利于公司产品销售渠道的拓展,并节省大量的广告宣传和经营运营成本,更好地把握商机.
品牌营销网站建设是指为了推广和宣传公司的品牌形象、提高品牌知名度和扩大产品销售等目的而创建的一个专业网站。这种网站设计和内容策略方案旨在确保网站的视觉效果和用户体验,并且通过搜索引擎优化(SEO)和社交媒体整合等手段来吸引更多的潜在客户访问网站。品牌营销网站建设需要考虑用户需求、品牌定位、市场趋势等多重因素,以确保网站能够达到预期的营销目标。同时,这也是一项长期的工作,需要不断更新和完善网站内容和功能,以适应市场变化和用户需求的变化。
集团站群包括官方网站、子品牌网站、分支机构网站等。确定网站类型有利于后续的网站规划和设计。
响应式设计是一种能够让网站在不同设备上(如电脑、平板和手机等)都能够自适应地显示,并保持良好的用户体验的设计方法。这意味着网站的布局、字体大小、图片尺寸和导航栏等元素会根据设备屏幕的大小和方向自动调整,以便于用户阅读和操作。 H5是HTML5的简称,是一个用于创建和展示网页内容的标准语言。与旧版本的HTML相比,HTML5提供了更多的新功能和API,使得开发者可以更加轻松地实现各种交互效果和媒体元素,从而提升网站的质量和用户体验。
模板建站是一种利用现成的网站模板来快速创建和设计新网站的方法。 模板是预先设计好的网站布局和样式,您可以选择一个符合您需求的模板,然后根据您的需要进行修改和定制,比如更改颜色、字体、图片等等。 这种方法可以节省时间和成本,因为您不需要从头开始设计和编写代码,而是可以利用现成的模板来快速创建一个漂亮和功能齐全的网站。
政府门户网站是政府部门信息发布的总平台,也是政府部门集中对外提供服务的总平台,这个平台能够为政府提供虚拟主机、电子邮件、信息检索等服务;能通过导航程序在技术、功能等方面实现网站间有机衔接;能对政府部门的网站域名、应用项目、网页风格、电子邮箱、连接方式、数据结构等进行统一规划、管理;能起到政府对外宣传和招商引资的作用;能为广大公众在网上浏览咨询直接办事提供服务,把电子政务推进到实用阶段。
3G时代的到来使得移动互联网在不断快速的发展,目前位置,使用手机上网的人数在剧烈的猛增,手机等手持移动设备已经成为网民上网常用方便的方式,这个发展给企业带来了无可限量的商业价值。 但是到目前为止,拥有营销型手机网站的企业并不多,并且那些传统PC端网站使用在手机上面的显示效果却不是特别的好,这就使得用户的体验度大大的降低了,企业要想要想更好的抓住未来移动端多带来的优势,为自己的企业建设营销型手机网站已经迫在眉睫
外贸网站(Foreign Trade website)常用于外贸企业对外贸易时候使用,使用客户群体为国外用户。外贸网站的类型常见有展示型网站和营销型网站,和国内常见网站类型大同小异。
如您有任何关于企业建站的未知问题,请用您手机微信或者QQ扫码二维码并添加我们为好友咨询!
微信扫一扫 建站资深客服-徐姐
微信扫一扫 建站资深销售-小波
微信扫一扫 网络资深销售-佳哥
手机QQ扫一扫 建站资深客服-徐姐
手机QQ扫一扫 建站资深销售-小波
你的消息已发送成功。
抱歉,出了一些问题。